为造谣现实通讯范畴带来了调动性艰涩
(映维网Nweon 2025年12月25日)理念念的数字辛勤呈现体验需要精准地复制一个东谈主的肉体、服装和动作。为了拿获研究动作并将其调动到造谣现实中,不错弃取自中心(第一东谈主称)的视角,这使得无需前视录像头即可使用便携式且具有资本效益的劝诱。然而,这带来了诸如禁闭和误解的肉体比例等挑战。
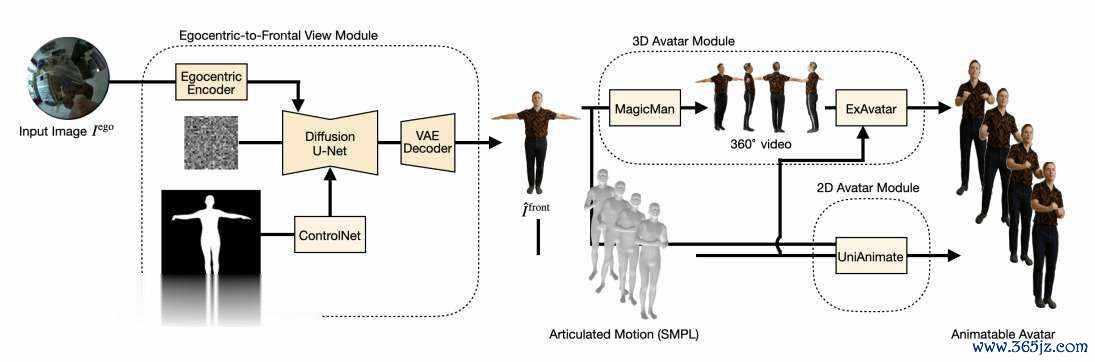
受SiTH和MagicMan等从正面图像进行360度重建的形式的启发,索尼团队引入了一个管谈,使用ControlNet和雄厚扩散骨干从装束的从上至下图像生成传神的正面视图。团队的方针是将单个从上至下的以自中心的图像退换为现实的正面暗意,并将其输入到图像-畅通模子中。这使得从最小的输入生成的化身畅通,铺平了谈路,更易于探望和通用的辛勤呈现系统。
这项技能完了了仅凭单个头戴录像头拍摄的鸟瞰角图像,就能生成具备精良服装纹理和竣工肉体结构的可动画数字化身,队造谣现实通讯范畴具有伏击真谛。

传统造谣现实通讯系统需要依赖复杂的多录像头阵列或专科动捕劝诱,才能创建实在的数字东谈主形象。这不仅资本昂贵,也限度了应用的普及性。尽管比年来出现了基于单目次像头的处分有筹谋,但它们大多依赖于传统的正面视角,无法灵验处理头戴式录像头私有的鸟瞰角图像。
头戴式录像头天然资本便宜且易于集成,但其拍摄的图像存在三个中枢挑战:严重的肉体装束(下半身和背部险些不想法)、非程序的透视角度(从上往下的畸变视角),以及误解的肉体比例。这些身分使得现存的图像到化身生成形式,如ExAvatar、AnimateAnyone等齐难以径直应用。
EgoAnimate的中枢创新在于将复杂的生成任务剖析为两个相对独处且可优化的阶段。第一阶段专注于处分最具挑战性的视角退换问题,将严重装束的鸟瞰图退换为了了的正面T姿势图像。第二阶段则诳骗现存的先进动画生成技能,基于退换后的正面图像创建最终的可运滚上路。
这种模块化想象不仅缩短了举座任务的复杂度,还使得系统梗概活泼适配不同的动画生成有筹谋。商量团队的方针不是从头发明轮子,而是通过处分最关键的瓶颈问题——视角退换,来开释现存技能的后劲。
视角退换模块是EgoAnimate系统中最具技能创新的部分。模块基于Stable Diffusion架构,但进行了多项关键修订。
在编码阶段,系统弃取双重编码机制。领先,输入的512×512鸟瞰角图像通过冻结的VAE编码器被压缩到潜空间,造成基础的视觉暗意。与此同期,湮灭图像还通过CLIP视觉编码器索要高层语义特征。这些特征经过线性投影和空间推广后,通过交叉戒备力机制注入到去噪U-Net中。这种想象使得模子梗概贯串输入图像的语义现实,并据此臆度被装束区域的外不雅。
为了确保生成的东谈主体结构准确,团队引入了ControlNet进行姿态抵制。该汇集以方针东谈主体的SMPL姿态掩码算作条目输入,将其编码为空间特征图后,径直添加到U-Net的残差流中。这特殊于为生成经由提供了一个精准的东谈主体骨架蓝图,确保输出图像中的东谈主体比例和姿态适合剖解学范例。
在测验计谋方面,团队弃取了复合失掉函数,将传统的噪点预测失掉与LPIPS感知失掉链接结。这种组合迫使模子不仅在像素层面接近实在正面图像,更在视觉感知上保证生成成果的合感性与天然度。消融实考发挥,加入感知失掉后,生成图像的视觉质地得到权贵擢升。
在获取高质地的正面T姿态图像后,EgoAnimate提供了两种不同的动画生成旅途供弃取。
3D高斯化身旅途旨在生成可被当代游戏引擎和渲染系统径直使用的3D数字东谈主。研究旅途领先使用MagicMan模子将单张正面图推广生成包含20个角度的多视图图像序列,其中包括RGB图像和对应的法线贴图。随后,这组图像被输入至基于3D高斯溅射的ExAvatar系统中,重建出可运转的3D化身。天然这条旅途能产出信得过的3D模子,但团队发现MagicMan生成的多视图存在细微伪影,导致最终化身的视觉保真度有所失掉。
2D视频化身旅途则绕过复杂的3D重建经由,径直生成动画视频序列。商量团队系统性地评估了多个前沿的图像到视频模子,包括MimicMotion、StableAnimator和UniAnimate。经过41名参与者的盲测评估,UniAnimate在服装一致性、畅通实在感和动画畅达度三个维度上均阐扬最好。尽管其生成速率相对较慢(以ExAvatar为基准1.0,UniAnimate为22.5),但输出质地的上风使其成为团队的最终弃取。
高质地的测验数据是EgoAnimate告捷的关键。为了处分鸟瞰-正视配对数据稀缺的问题,商量团队自主构建了一个特地的数据集。
数据集聚经由中,参与者捎带装有录像头的头盔来获取鸟瞰角图像,同期使用外部录像头同步拿获正面视图。总共系统无需深度传感器或多视角阵列,大大缩短了集聚复杂度。通过期分戳和肉体姿态匹配,每个正面图像与毛糙10张不同的鸟瞰帧诞生对应关联,灵验引入了畅通千般性。
值得戒备的是,团队使用现成的扩散模子对正面图像进行了后处理增强,改善光照条目和视觉传神度。天然这些增强图像并非严格真谛上的实在数据,但它们为模子测验提供了更了了的监督信号,权贵擢升了生成质地。
在定量评估中,EgoAnimate在多个方针上均阐扬出色。在图像生成质地方面,其在PSNR、SSIM和LPIPS三个程序方针上均优于基线模子。特地引东谈主疑望的是在服装还原准确率上的阐扬:在分手短裤与长裤的任务中达到87%的准确率,在分手T恤与毛衣的任务中达到79%的准确率,这发挥了模子对语义现实的深远贯串。
更令东谈主印象深远的是模子的泛化才能。尽管测验时仅战役过自集聚的数据集,EgoAnimate在澈底未参与测验的Ego4D数据集、汇集下载的Instagram图片,致使是动态复杂的公园跑GoPro素材上,齐能告捷生成合理的动画化身。这种宏大的跨数据集泛化才能标明,模子学习到的是普适的视角退换旨趣,而非对测验数据的纯粹追想。
EgoAnimate技能的出现为多个范畴带来了新的可能性。在造谣现实酬酢平台中,用户不错快速创建与我方外不雅一致的数字化身,无需专科劝诱即可完了高千里浸感的互动。在辛勤配合场景下,参与者梗概以更天然的神色进行疏浚,传递丰富的非说话信息。
天然,商量团队同期坦诚指出了现时技能的局限性。数据聚集东谈主体体型、肤色和服装格调的千般性仍有待擢升,这关联到技能的平允性和普适性。由于鸟瞰角底下部信息严重缺失,系统主动烧毁了对面部区域的建模,这在需要颜料疏浚的场景中是个彰着短板。关于长款大衣、裙摆等具有复杂几何结构的服装,模子的还原才能仍有擢腾飞间。
预测改日,团队贪图通过引入时序信息来处理动态服装,探索基于短视频片断的一致性生成。面部区域的收复亦然一个伏击所在,可能通过连结生成式先验与部分可见信息来完了。跟着技能的进一步完善,EgoAnimate有望成为下一代造谣现实通讯的基础技能,让每个东谈主齐能以最天然的神色在数字天下中呈现自我。
研究论文:EgoAnimate: Generating Human Animations from Egocentric top-down Views
总的来说,EgoAnimate代表了单视角数字东谈主生成技能的伏击高出。通过高明地连结前沿的生成模子与模块化想象理念,它发挥了从最小化、最易得的传感器输入中创建高质地动画化身的可行性。这项商量不仅为学术社区提供了新的商量所在,同期为产业界开发普惠型VR/AR应用提供了实用的技能旅途。